Make Way for AI-Readable Codebases

Introduction: The Overwhelmed Developer CEO
In the early days of Ceedar, around last November, we were (still are!) a small, two-person startup with big ambitions. Like many startups, we were working hard to increase our productivity without the luxury of adding more people to the team. As CEO, I had to balance many tasks, including writing code while also running the business. So, I began experimenting with AI coding tools like aider.chat, hoping they would allow me to ship features faster and avoid hiring additional developers.
At first, the AI coding tools seemed like a dream come true. But it didn’t take long for that illusion to crack. I started running into major issues—problems that didn’t just slow me down, but made me wonder if I was actually being any more efficient at all.
The Problem: The AI Struggles with Code Context
The problem became obvious as I worked with the AI. I realized that the AI wasn’t able to understand my code structure well enough to make meaningful changes. The root of the issue was how I had organized my codebase. Back then, I used the classic stack-layer structure, where different layers like endpoints, business logic, and database calls were all grouped together. This structure worked well enough for human developers (did it tho?), but for the AI, it was too much context at once.
The AI would struggle to navigate the code, often touching parts that were irrelevant or unnecessary. For example, it would try to generate code but fail to import the right dependencies. Worse, when it couldn’t find a type definition or a piece of context, it would just invent one. This resulted in code that accessed non-existent properties of structs, breaking things in subtle but frustrating ways. I found myself spending more time fixing the AI’s mistakes than if I had written the code myself from scratch.
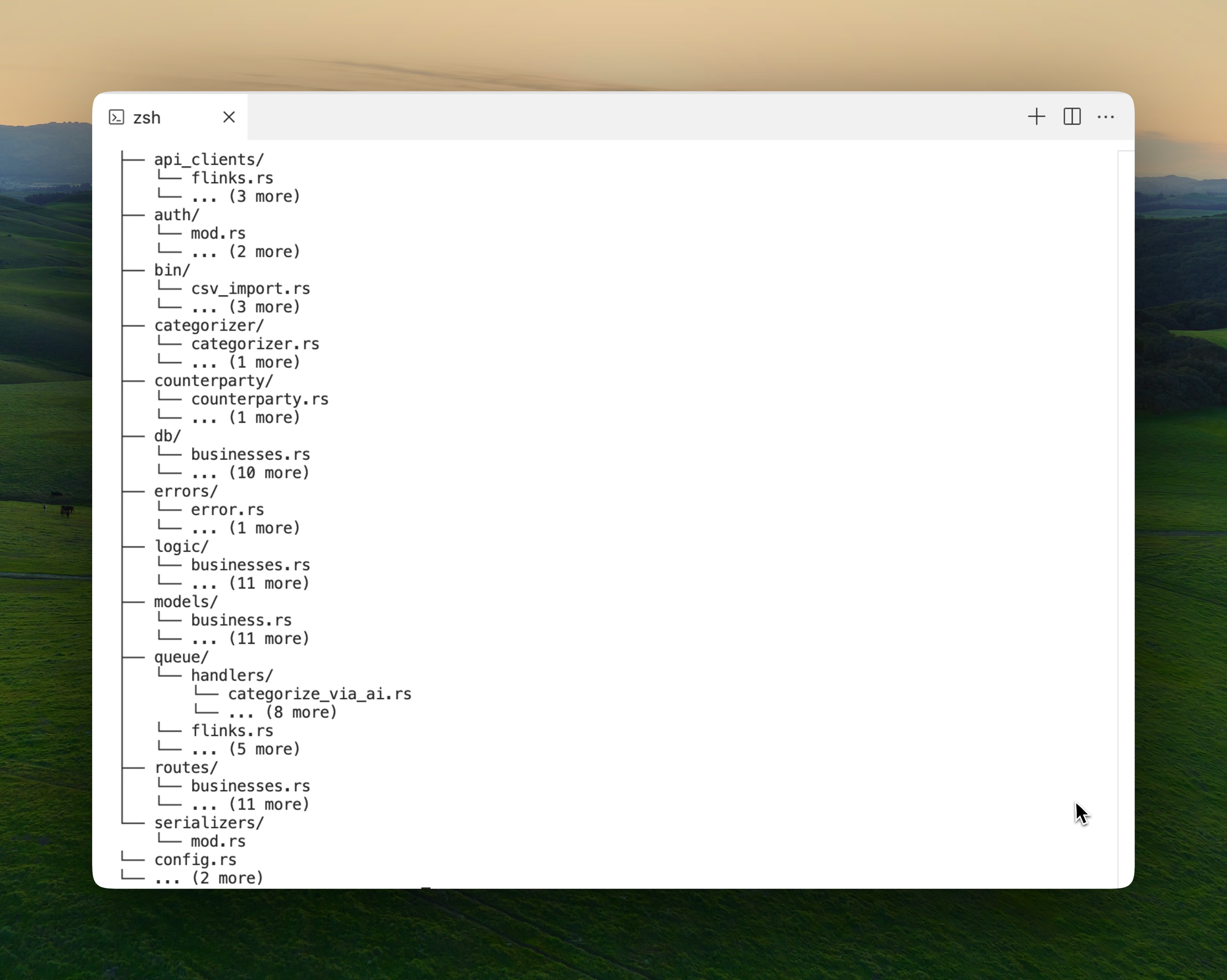
The Turning Point: Organizing by Feature, Managing Costs, and Setting Conventions
After dealing with these inefficiencies for long enough, I started looking for a solution. That’s when I had a crucial realization: the AI could handle a smaller, more focused context much better than larger, multi-layered files. If I could limit the code it was working with to just what was relevant, I could avoid the confusion and errors that came from giving it too much information.
But it wasn’t just about efficiency—there was also a financial cost to consider. As any startup founder knows, running lean is critical to survival. Tokens, the currency of AI context, cost money. Passing unnecessary tokens or processing more context than required can quickly add up in financial terms. I realized that by reducing the amount of code I fed the AI, I wasn’t just improving its performance; I was also lowering my operational costs.
By keeping each feature self-contained, I drastically reduced both the amount of context the AI had to process and the number of tokens I had to pay for. In a small startup, every dollar counts, and this approach helped me stay efficient while keeping expenses low. I went through quite some effort to do a major refactor, hoping for the payoff, and it has paid off so many times over.
While the example I’ve been working with here is focused on our API, I’ve found that the same principles hold true for our front-end code as well. Whether it’s handling API logic or user interface components, organizing by feature—keeping all the related logic in one place—has made a significant difference in both efficiency and clarity.
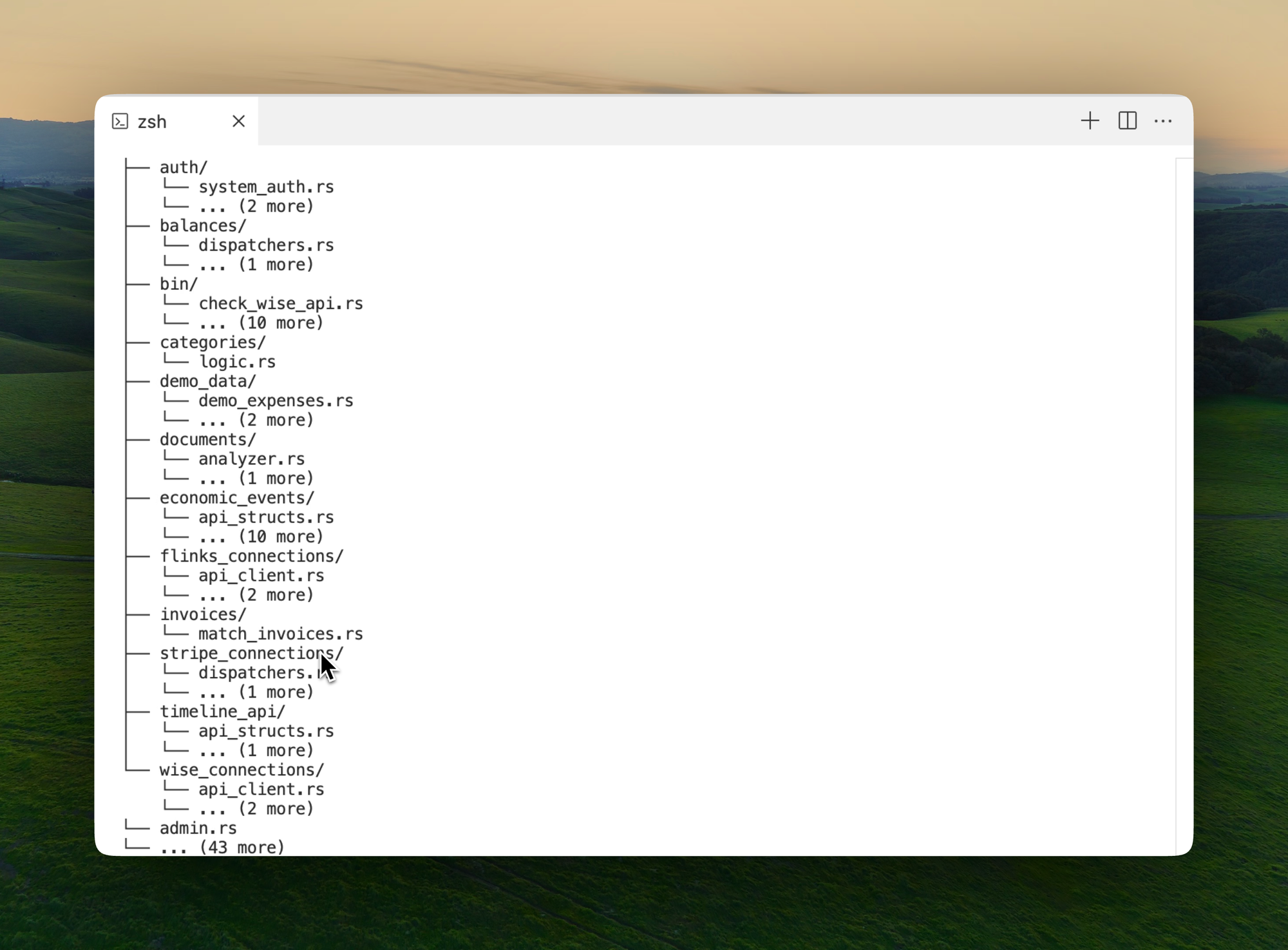
A Thought on Stack Layers: A Conversation Starter
Recently, I came across a new boilerplate called v1.run by the folks building the open-source Midday product, which follows the stack-layered approach to organizing code. Take a look in the 'packages' folder to see what I mean. It’s a well-constructed approach, and I can certainly see why developers might opt for this kind of structure, especially if they’re used to dividing their work across layers like endpoints, business logic, and database calls.
However, after working extensively with AI coding tools, I’ve found that this traditional stack-layer structure can create unnecessary friction—both for the AI and for developers. When everything is separated by layers, it can be difficult to maintain a clear context, and AI models, in particular, seem to struggle with making sense of the whole system.
That’s why I’d like to start a conversation around the merits of organizing code by feature rather than by stack layers. In my experience, tightly binding everything related to a specific feature into a single file or folder dramatically reduces the cognitive overhead for both humans and AI. It keeps the context clear and the dependencies obvious, which leads to fewer errors and faster development cycles.
That said, this isn’t about dismissing the stack-layered approach. I’m curious to hear from others, especially those who’ve used structures like v1.run, about their thoughts on how these different organizational strategies can complement or even improve one another—especially when working with AI tools in today’s development environment.
The Transformation: Regaining Efficiency and Control
The impact of the change we'd made was immediate and profound. Suddenly, the AI stopped making wild guesses and unnecessary changes. It became a much more reliable partner in the development process. I could add a single file or folder to its context window, write a prompt for a new feature or change in business logic, and trust the AI to follow the example of the code I had already written. With aider, the tool I was using, it would actually make commits with each iteration, streamlining my workflow even further (you can revert any change easily at any time).
The AI's ability to make surgical edits based on clear, focused context was a game-changer. Instead of spending hours fixing broken code, I could spend more time on higher-level tasks, like steering the business or developing new ideas. As CEO, I knew that coding wasn’t my only responsibility, and this new structure allowed me to stay productive without getting bogged down by code issues. I didn’t have to hire more people, and yet we were still shipping new features faster than ever.
Conclusion: The Power of a Well-Structured Codebase
Looking back, the real lesson here wasn’t just about improving how I organized the code—it was about building a system that could work seamlessly with AI. By focusing on a feature-based organization and maintaining consistent conventions across the codebase, I unlocked the true potential of the AI tools.
This structure didn’t just make the AI better at its job—it made me better at mine. It allowed me to balance coding with the many other demands of running a startup. By freeing myself from the chaos of a disorganized codebase, I reclaimed time, energy, and focus.
For other developers and founders out there, the message is clear: if you want to make AI an effective part of your workflow, it’s not enough to just use the tools. You need to structure your code in a way that the AI can understand—and that starts with making it as readable and consolidated as possible.
b.t.w. for the uninitiated, don't forget to use Claude Sonnet 3.5. that's where the magic happens